데이터 분석의 첫걸음, CRISP-DM 제대로 알기
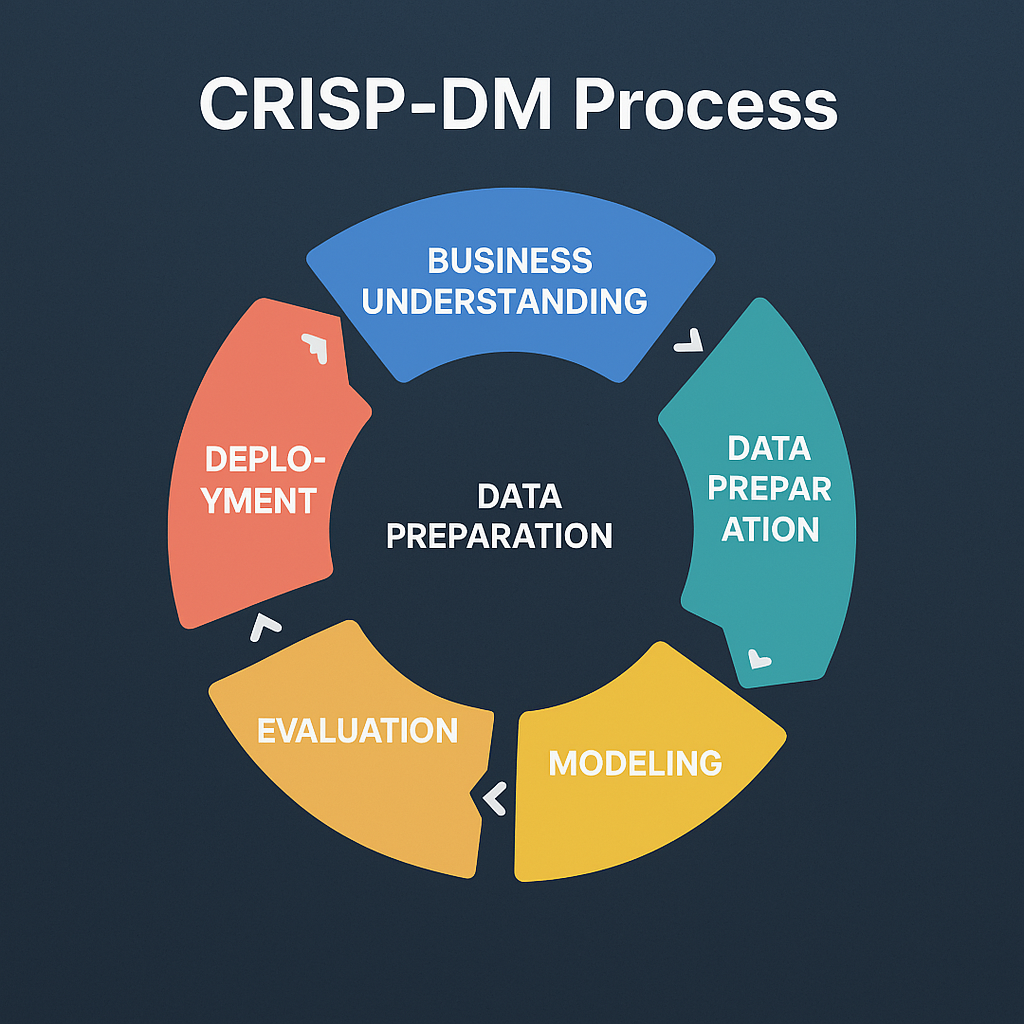
CRISP-DM(Cross Industry Standard Process for Data Mining)은 데이터 마이닝 및 분석 프로젝트를 수행할 때 널리 사용되는 표준 프로세스 모델이다.
다양한 산업 분야에서 활용할 수 있도록 설계된 이 모델은 비즈니스 목표 설정부터 모델 배포까지 전 과정을 체계적으로 구조화한다.
CRISP-DM은 반복적인 프로세스이고, 특정 단계에서 문제가 발생하면 이전 단계로 돌아가 다시 조정할 수 있도록 구성되어 있다. 즉, 단순한 일방향 프로세스가 아니라, 지속적인 개선과 피드백을 반영하는 방식이다.
이번 글에서는 CRISP-DM의 6단계를 설명하고, 실제 프로젝트에서 이를 어떻게 적용할 수 있는지 예시를 들어 살펴본다.
🔹 CRISP-DM의 6단계
비즈니스 이해 (Business Understanding)
데이터 분석 프로젝트의 최종 목표를 정의하는 단계이다.
기술적인 접근보다 비즈니스 관점에서 문제를 정의하고, 어떤 결과를 원하는지 명확히 해야 한다.
1단계 주요 활동:
- 프로젝트 목표 수립
- 주요 비즈니스 문제 정의
- 분석을 통해 얻고자 하는 가치 정리
- 프로젝트 성공 기준 설정
예시:
"회사 서비스의 고객 이탈을 예측하여 이탈 가능성이 높은 고객에게 맞춤형 혜택을 제공하자!"
"공공데이터 분석을 통해 AI 데이터센터의 최적의 입지를 선정하자 "
데이터 이해 (Data Understanding)
데이터를 수집하고 탐색하는 과정이다.
데이터의 구조, 품질, 분포를 파악하고, 이상치와 결측치를 탐색한다.
2단계 주요 활동:
- 데이터 수집 및 탐색
- 변수(Feature) 및 데이터 속성 이해
- 데이터 시각화 및 분포 확인
- 데이터 품질 검토 (결측값, 이상치, 중복 데이터 등)
예시:
고객 ID, 연령, 성별, 구매 이력, 방문 횟수 등의 데이터가 있으며, 결측값과 이상치가 포함되어 있는지 확인해야 한다.
이해를위한 분석과정 - EDA & CDA 이란?
1. EDA (Exploratory Data Analysis) - 탐색적 데이터 분석
목적: 데이터에 대해 더 잘 이해하고, 패턴이나 이상치를 발견하려는 과정이다.
- 분석 방법: 그래프나 통계적 기법을 사용하여 데이터를 시각적으로 살펴본다.
- 주요 활동:
- 데이터의 분포, 평균, 표준편차 등 기본적인 통계 값 확인.
- 히스토그램, 상자그림, 산점도 등의 그래프를 활용하여 데이터의 특성 파악.
- 결측치, 이상치 등의 문제를 찾아냅니다.
간단한 예:
데이터가 있고, 그 데이터가 어떤 특징을 갖고 있는지 파악하려고 한다.
예를 들어, 특정 제품의 판매 데이터를 분석할 때 판매량이 높은 날과 낮은 날의 차이를 확인하고 싶다면,
EDA를 통해 이를 시각화하거나 통계적으로 분석할 수 있다.
2. CDA (Confirmatory Data Analysis) - 확인적 데이터 분석
목적: 특정 가설을 검증하는 과정이다. 즉, 이미 예상한 바를 통계적으로 증명하거나 반박하는 분석이다.
- 분석 방법: 가설 검정을 통해 데이터를 분석하여 가설이 맞는지 확인한다.
- 주요 활동:
- 가설 설정 (예: "A 제품의 판매량은 B 제품보다 높다").
- 통계적 검정을 사용하여 이 가설이 맞는지 확인 (검정의 예시지표 → t-검정, 카이제곱 검정 등).
간단한 예:
A 제품의 판매량이 B 제품보다 높다고 주장할 때, 그 주장에 대한 증거를 통계적으로 확인하는 것이 CDA이다.
이를 위해 데이터를 분석하고, 통계적으로 유의미한 차이가 있는지를 확인한다.
진행 방식은 EDA → CDA으로 실시한다.
데이터 준비 (Data Preparation)
분석을 위해 데이터를 정제하고 변환하는 과정이다.
모델이 올바르게 학습할 수 있도록 데이터를 전처리하고, 필요에 따라 피처 엔지니어링을 수행합니다.
주요 활동:
- 결측값 처리 (평균 대체, 삭제, 직전 값 대입)
- 이상치 제거
- 범주형 데이터 변환 (원-핫 인코딩, 라벨 인코딩)
- 데이터 정규화 및 스케일링
- 필요 없는 변수 제거 및 새로운 변수 생성
- 가변수화
예제:
고객 연령 데이터를 표준화(Scaling)하고, 범주형 변수를 원-핫 인코딩(One-Hot Encoding) 방식으로 변환한다.
모델링 (Modeling)
머신러닝 또는 통계 모델을 구축하는 단계이다.
적절한 알고리즘을 선택하고, 모델을 학습(training) 및 평가(validation)하여 최적의 성능을 찾는 과정을 진행한다.
주요 활동:
- 알고리즘 선택 (의사결정나무, 랜덤포레스트, XGBoost 등등)
- 학습 데이터와 테스트 데이터 분리 (데이터 로더 함수 사용하기)
- 모델 학습 및 검증
- 하이퍼파라미터 튜닝 (Grid Search, Random Search 등등)
- 성능 비교 및 최적 모델 선정
예제:
고객 이탈 예측을 위해 로지스틱 회귀, 랜덤 포레스트, XGBoost 모델을 비교한 후 가장 성능이 좋은 모델을 선택한다.
평가 (Evaluation)
모델이 비즈니스 목표에 적합한지 평가하는 단계이다.
단순히 정확도만 보는 것이 아니라, Precision, Recall, F1-score 같은 다양한 지표를 분석하여 모델 성능을 평가한다.
주요 활동:
- 모델 성능 평가 (정확도, F1-score, AUC-ROC 등)
- 비즈니스 목표와의 일치 여부 검토
- 모델 개선 필요 여부 판단
- 이해 관계자와 결과 공유
예제:
모델의 F1-score가 90% 이상이면 만족, 그 이하라면 모델을 다시 개선한다.
배포 (Deployment)
최종 모델을 실제 서비스나 시스템에 적용하는 단계이다.
모델을 API 형태로 배포하거나, 실시간 예측 시스템을 구축할 수도 있다.
또한, 모델 성능을 지속적으로 모니터링하고 필요하면 업데이트하는 과정도 포함된다.
주요 활동:
- 모델을 실제 서비스 환경에 적용
- 모델 추론 API 또는 대시보드 개발
- 실시간 데이터 반영 및 업데이트 시스템 구축
- 지속적인 모니터링 및 유지보수
예제:
고객 이탈 예측 모델을 배포하고, 특정 고객이 이탈 가능성이 높으면 자동으로 할인 쿠폰을 제공하는 시스템을 개발한다. (쿠팡이나 멜론 정기결제 같은~ )
🔥 GPT가 말아주는 CRISP-DM의 핵심 정리
✅ 비즈니스 목표 설정부터 배포까지 체계적인 접근 방법 제공
✅ 모델링만이 아니라 데이터 이해 및 준비 과정도 중요
✅ 반복(iterative) 프로세스 → 필요하면 이전 단계로 돌아가 수정 가능
✅ 다양한 데이터 분석 및 머신러닝 프로젝트에 활용 가능
📌 CRISP-DM을 활용하는 산업 분야
- 마케팅: 고객 세분화, 이탈 예측
- 금융: 사기 탐지, 신용 점수 평가
- 헬스케어: 질병 예측, 환자 관리
- 제조업: 품질 예측, 장비 고장 예측
마무리
결론 : CRISP-DM은 비즈니스 목표를 데이터 분석으로 해결하기 위한 가장 체계적인 접근 방식 중 하나이다.
데이터 분석 프로젝트를 진행할 때 CRISP-DM을 참고하면 데이터 탐색부터 모델 배포까지 명확한 프로세스를 따를 수 있어 보다 효과적인 분석이 가능하다.
앞으로 개인 데이터 분석 프로젝트나 공모전을 위한 프로젝트때 사용해볼 것이다.